Processing and Logic¶
Processing and Logic provides a programming environment to perform calculations, make decisions and take actions.
Some examples include:
- Calculate average of multiple Parameters
- Transform a series using an equation
- Generate a series forecast to provide predictive alarming
Programs are expressed as JavaScript, stored as configuration in Process Nodes, and executed on a schedule or automatically as new data is acquired. Each program can interact with all Nodes in the current Workspace and any associated time-series data.
Process Nodes¶
There are two types of Nodes that can have a program defined as part of their configuration. The first is a Process Parameter that allows you to transform existing data; the second is a type of Data Source called a Processor that allows you to create new data values.
A program should include three distinct stages:
- Define input nodes (using the NODE, NUMBER, TEXT, TIME or BOOLEAN functions)
- Apply processing to input nodes (or associated time-series data)
- Output results (either by returning a value or setting an attribute of a node)
| Process Parameter | Processor | |
|---|---|---|
| Node Type | Parameter | Data Source |
| Number of inputs | 3 | 25 |
| Number of outputs | 1 | 100 |
| Execution trigger | On input update | On input update or schedule |
| Maximum Duration | 0.2 seconds | 2 seconds |
| Output timestamps | Defined by first input | Defined by first input or schedule |
 Process Parameter¶
Process Parameter¶
A Process Parameter is a type of Parameter that has a program defined as part of it’s configuration and can be created under any Data Source. The first input referred to by the program (known as the primary input) will be used to define the timestamps used by the output of the process. Each execution of the program must return a single output value of the expected type. This output can then be viewed in the same way as any other Parameter (for example, it can be shown as a table or chart, exported, used as input for a different process etc.). The output can also have states defined which will trigger alarms.
Examples¶
1 2 3 4 5 6 | // Calculate the average currentValue of Parameters from different Locations
var param1 = NODE('Location 1/Source/Param');
var param2 = NODE('Location 2/Source/Param');
var param3 = NODE('Location 3/Source/Param');
return (param1 + param2 + param3) / 3;
|
1 2 3 4 5 6 7 8 | // Transform the currentValue of Param using a 3rd order polynomial
var a = 7.24;
var b = -10.004;
var c = 4.328;
var d = -0.4667;
var v = NODE('Param').currentValue;
return a + (b*v) + (c * Math.pow(v,2)) + (d * Math.pow(v,3));
|
1 2 3 4 5 6 7 8 9 10 11 | // Assign a bad quality code to value spikes and offset the timestamp by one hour
var param = NODE('Param');
var ts = T(param.currentTime).subtract(1,'hours');
var v = param.currentValue;
var q;
if( v > 999 ) {
q = 156;
}
return {"time": ts,"value": v,"quality": q};
|
Note
Assigning quality codes to value spikes can also be achieved by configuring the Quality of a Parameter State.
 Processor¶
Processor¶
A Processor is a type of Data Source containing a program that generates multiple output values, which are stored as new Parameters. The timestamps of the output data can be generated by scheduling the execution of the process, in the same way that data acquisition of a regular Data Source can be scheduled. Alternatively, the timestamps can be defined by the first input, just as with Process Parameters.
Output Creation¶
Outputs are defined as part of your program and automatically created as Parameters under your Processor when the program is saved. To update a Processor output, use one of the four Node creation functions (NUMBER, TEXT, TIME or BOOLEAN) to obtain a reference to the output, then assign a value to a specific attribute, e.g. TEXT('output').currentValue = "Hello world";.
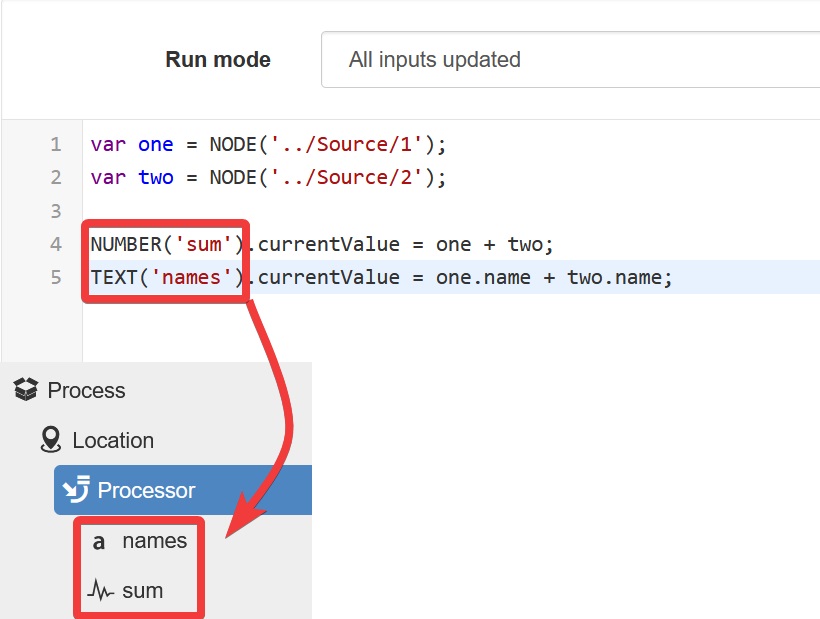
Examples¶
1 2 3 4 5 6 | // Assign values to multiple outputs
var quotient = NODE('../Source/Param') / 5;
var remainder = NODE('../Source/Param') % 5;
NUMBER('quotient').currentValue = quotient;
NUMBER('remainder').currentValue = remainder;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 | // Assign a bad quality code to value spikes and offset the timestamp by one hour
var param = NODE('Param');
var output = NUMBER('Output');
var q;
if( v > 999 ) {
q = 156;
}
// NOTE: currentTime & currentQuality must be assigned prior to currentValue
output.currentTime = T(param.currentTime).subtract(1,'hours');
output.currentQuality = q;
output.currentValue = param.currentValue;
|
1 2 3 4 5 6 7 8 9 10 | // Calculate average currentValue of all nodes ending with Temperature in the current Workspace
var sum = 0;
var temps = NODES(WORKSPACE + '/.*Temperature');
var avg = NUMBER('Output');
for( var i=0; i<temps.length; i++ ) {
sum = sum + temps[i];
}
avg.currentValue = sum / nodes.length;
|
Environment¶
Global Variables¶
Global variables are references to Nodes and other values that are related to the currently executing process.
| NOW | Current timestamp being evaluated by the process |
| THIS | Reference to currently executing Process Node |
| SOURCE | Reference to Data Source of currently executing process |
| LOCATION | Reference to Location of currently executing process |
| WORKSPACE | Reference to Workspace of currently executing process |
Global Functions¶
Global functions can be used to obtain a reference to a Node, authorize access to a Workspace or convert a time expression.
| NODE( path ) | Retrieve node by path |
| NODES( path expr ) | Retrieve one or more nodes by path expression A path expression begins with an ordinary path and includes a regular expression suffix matching one or more node names, e.g. retrieve all workspace nodes ending with input:
Retrieving nodes from outside the current Workspace is not supported |
| NUMBER( path ) | Create or retrieve NUMBER Parameter by path |
| TEXT( path ) | Create or retrieve TEXT Parameter by path |
| TIME( path ) | Create or retrieve TIME Parameter by path |
| BOOLEAN( path ) | Create or retrieve BOOLEAN Parameter by path |
| AUTH( slug, api-key ) | Authorise access to a Workspace using an API key |
| T( expr ) | Convert a time expression to a Moment.js timestamp A time expression can be any of the following:
|
| Q( name ) | Convert a quality name to a quality code |
Paths¶
A path describes a reference to a Node and can be expressed as an absolute path, or a path that is relative to the current Process Node. Standard UNIX style path syntax is used, so .. refers to the parent Node in the Workspace tree.
In addition to using names to identify Nodes, a path may also contain either a Node Id or Custom Id. Named elements may also be included after the Node identifier. Note that Node identifiers should be enclosed by braces when included in a path, e.g. {5ae92a139097830ee5711d94} or {@customId}.
| Examples | |
/Workspace/Location/Source/Parameter |
Absolute path to a Parameter |
../Location 2/Source/Parameter |
Path to a Parameter, relative to the Process Node |
{5b6a3fc24e960d0e7497b4b4} |
Path to a Node, identified by Node Id |
{@myParam} |
Path to a Parameter, identified by Custom Id |
{5ae92a139097830ee5711d94}/Parameter |
Path to a Parameter, relative to Source Node Id |
{@mySource}/Parameter |
Path to a Parameter, relative to Source Custom Id |
Workspace Authorisation¶
Paths that reference a Node outside the current Workspace (including Nodes in other accounts) require authorisation to verify your process has the appropriate permission. This is achieved using the AUTH function, which must be used in your progam before referencing any Nodes from the foreign Workspace.
The AUTH function declares an association between an account identifier (or slug) and an API key. The slug for an account is visible in your browser address bar, immediately preceeding the Workspace name, when any Node is selected.

The following code snippet demonstrates declaring authorisation to an account (with slug abc123) and accessing a Node within the foreign Workspace.
1 2 3 4 | // Authorise access to a node in a foreign Workspace
AUTH('abc123','eM1i7Pugp8EpSQNLAXiDT3DJJUAK2mOn17guVeTu');
return NODE('/abc123/Workspace/Location/Source/Parameter').currentValue;
|
Note
If all the Node paths in your program are in the same Workspace as your program, then the AUTH function is not required.
Aggregate Expressions¶
Aggregate Expressions provide a means of aggregating input data supplied to your program and may be optionally included as a suffix to any parameter path.
The three components of an aggregate expression must be expressed in order and separated by a semi-colon:
| Examples | |
Param 1 |
Raw data |
Param 1;AVERAGE;D;1H |
Hourly average |
Param 1;TOTAL;D+9H;1D |
Daily total calculated at 9am |
Param 1;COUNT;W;1W |
Number of values since the start of the week |
Node Attributes and Values¶
A Node reference can be used to access the attributes of that Node using dot notation, including the data value if the Node is a Parameter.
| Examples | |
LOCATION.name |
Name of the Location |
WORKSPACE.createdTime |
Creation time of the Workspace |
NUMBER("param1").offset |
Numeric offset of the Number Parameter |
NODE("param2").currentValue |
Current data value of the Parameter |
NODE("param3").newestTime |
Newest timestamp of the Parameter |
A full reference of Node attributes is documented as part of the HTTP API. Note that for calculations requiring the time of the newest value, this can be accessed via the newestTime attribute.
Implicit Node Values¶
Each type of Node reference can be used as an implicit value without using dot notation. For example, the implicit value field of a Parameter is currentValue, so the Node reference can be used as a direct substitue for the current data value of the Node. This means the following two statements will return the same result:
Statement 1, access the current data value of a Node reference using dot notation, add 10 and return the result:
return NODE("param1").currentValue + 10;
Statement 2, access the current data value of a Node reference using the implicit Node value, add 10 and return the result:
return NODE("param1") + 10;
The above example is able to treat the Node reference for param1 as if it were a number, because this Node is a Number Parameter. Note that the type of any specific Node is always the same regardless of how the Node is referenced. This means that using the global functions NUMBER("param1") and NODE("param1") will both return a Node reference of type Number Parameter, assuming param1 is a Number. Use care when relying on implicit Node values, because the implicit value field and type is different for different types of Nodes.
| Node Type | Implicit value field | Implicit value type |
| Number Parameter | currentValue |
Number |
| Text Parameter | currentValue |
String |
| Time Parameter | currentValue |
Time |
| Location | currentValue |
Array of [latitude,longitude] decimal values |
| Source | name |
String |
| Folder | name |
String |
| Workspace | name |
String |
Process Trigger¶
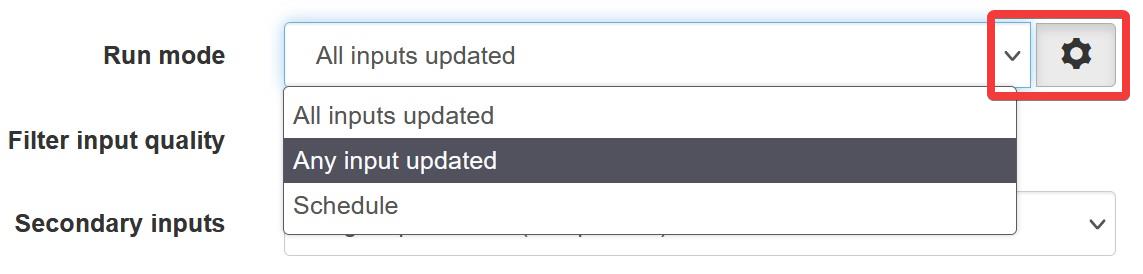
A process can be triggered to run in a number of ways:
| Schedule | At a configurable interval (Processor only) |
| Any input updated | When any input advances beyond the current time of the process |
| All inputs updated | When all inputs have advanced beyond the current time of the process |
| Acquire Now | User action (causes Process Parameters to recalculate entire series) |
Note
Each process timestamp is evaluated exactly once and only considers input data available at that time. Input data arriving after a process has advanced (e.g. Any input updated) may yield unexpected results.
Input Quality Filter¶
Input data to your program can be filtered according to its quality type to ensure only desired values are considered.
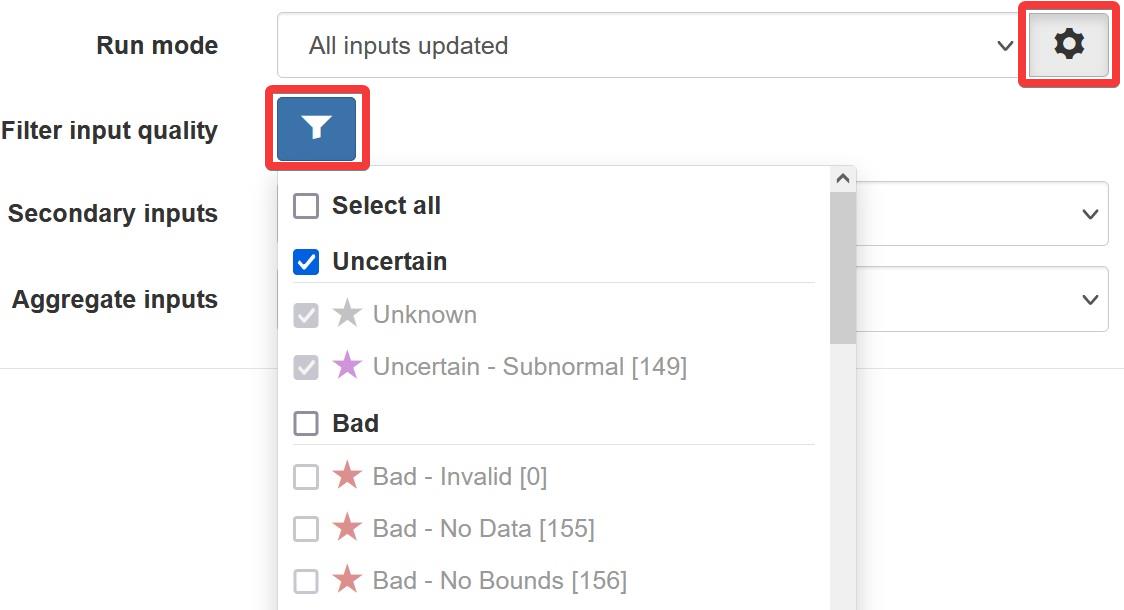
By default, your program will exclude quality types according to the Quality Codes configuration in your Account Settings. To ensure specific quality types are considered, a filter can be applied.
Secondary inputs¶
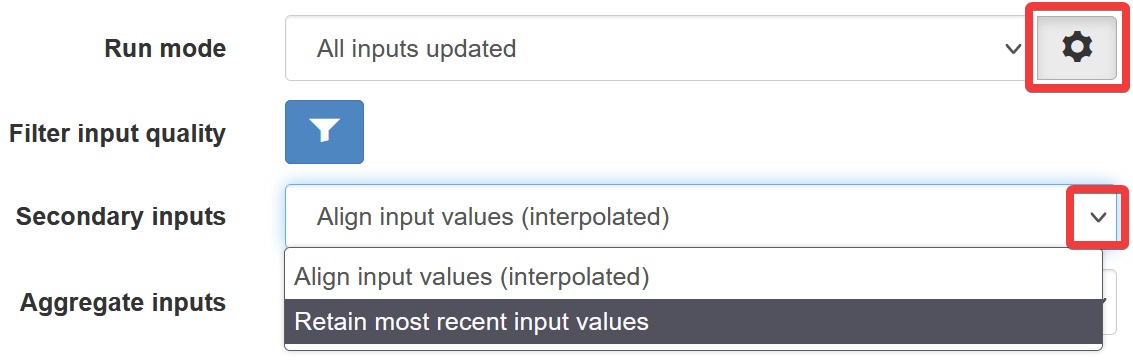
Secondary inputs may have records that occur at different times than the primary input, e.g. parameters from different data sources. Input data not aligned with the current execution timestamp can be interpreted by a process in two ways:
| Align input values (interpolated) | Secondary values interpolated to align with the current execution timestamp |
| Retain most recent input values | Secondary values prior to the current execution timestamp are retained |
Aggregate inputs¶
Process aggregate inputs will have values that occur at a defined interval. Process execution can be delayed until the latest aggregate interval is complete:
| Complete & partial intervals | Process will execute even during a partial aggregate interval |
| Complete intervals only | Process will only execute when the aggregate interval is complete |
Third Party Libraries¶
A number of useful third-party libraries have been included to simplify common processing operations. Please refer to the documentation provided by each library for specific examples.
| Library | Version | Description |
everpolate |
0.0.3 | |
moment |
2.22.2 | Parse, validate, manipulate, and display dates and times |
These libraries can be accessed by your program using the require keyword, for example:
var linear = require('everpolate').linear;
Process Alarm¶
A Process Alarm is raised when a Process Node encounters an error either during validation or execution. A subsequent successful validation or execution of the process will clear the alarm.
Errors¶
The two general category of errors that can be encounted with Proccessing and Logic are validation errors and runtime errors.
Validation Errors¶
Validation errors are caused either by incorrect syntax or some other error condition that can be detected. These errors are experienced as immediate feedback when validating a program, and contain a specific error message which can be used to remedy the problem. A program will not be executed until it can be validated without errors.
Runtime Errors¶
Runtime errors can occur during the execution of a program even when it validates successfully. For example, if an input node referenced by the program is deleted from the workspace, the program will no longer be able to run successfully. These types of errors will be expressed as process alarms, and will contain a specific error message to help remedy the problem.
It is also possible to manually trigger a Runtime Error by using the throw keyword in conjunction with a custom error message:
throw 'custom error message';
Best Practices¶
- Program syntax should confirm to ECMAScript 5.1
- Inputs should be declared before they are referenced, so that any line numbers in error messages will clearly refer to the declaration of a missing input.
- Very complex or time-consuming calculations may cause the process to exceed the allowed processing time limit.
- Any input that is referenced by a process will trigger execution of the process when that input is updated. Therefore, a large number of inputs being updated frequently or on different schedules can trigger a process to run very frequently. For example, if 9 inputs are updated every hour, but the 10th input is updated every minute, then the process will execute every minute.
- As the first referenced input is used to determine the output timestamp for a Process Parameter, the input which updates most frequently should be the first input.
- If the same algorithms are used repeatedly for different Process Nodes, this code should be expressed as a function and stored in the Workspace Shared Code.